Several KDL development team members contributed to the technical overview below including Arianna Ciula, Brian Maher, Tiffany Ong, and James Smithies.
Context
As detailed in the technical introduction of the 2008 edition of the facsimile component of the ncse project, ncse is large and varied resource, containing well over 400,000 articles that originally appeared in roughly 3500 issues of six nineteenth-century periodicals, published during a span of 84 years. Materials within the corpus exist in numbered editions, and include supplements, wrapper materials and visual elements. In 2005, when the project started, the key challenge for the technical partner in the project (at the time the Centre for Computing in the Humanities, King’s College London) was to create a digital system for the management of such a body of material that encompassed the design and development of an appropriate yet innovative set of tools to assist researchers in finding materials while also challenging and enabling new and innovative approaches toward research.
Over 13 years later, not only the technical partner has evolved institutionally into the new vestigia of King’s Digital Lab (KDL) but the key challenge for the project has also evolved into the pressing need to sustain a resource that, while widely used, had reached end of life. This was true for the 2008 edition of the facsimile component of the website which included granular browsing and faceted search functionalities built using the Olive software, not longer supported and upgradable.
The 2008 edition is formed of two integrated components: the 'Facsimile' component - a repository of full-page facsimiles and textual transcripts generated through Optical Character Recognition (OCR); and the 'Keyword' component - an index of semantic keywords and person, place and institution names, generated using data mining and natural language processing techniques. Both components of the system were released as fully searchable and include rich, bibliographic metadata attached to titles, volumes, issues, departments and articles within the edition. The periodicals were provided as facsimile page images which had been digitized from microfilm. The texts in ncse were scanned from microfilm by Olive Software, OCRed to render the texts searchable and processed using their Viewpoint software.
At its inception in 2015, KDL inherited just under 100 digital research projects and websites. Aware of the intellectual and cultural value of many of these projects, with the support of the Faculty of Arts and Humanities at King’s College London, KDL took on its responsibility to the community to steward them in a responsible manner. Research leads, the Faculty of Arts and Humanities at King’s College London, and partner institutions, played a crucial role in supporting this process.1
In the case of ncse, the site KDL inherited was hosted on Windows Server 2003 for Olive compatibility, which was long out of support and hence presented immediate and severe security risks (the WannaCrypt and Petya ransomwares in 2017 enforced the shutting down of Olive on KDL servers). Repeated attempts to contact Olive regarding updated versions of their software without Windows 2003 dependencies have been unsuccessful. Hence, the result of KDL assessment process on the ncse legacy site in 2017 was the recommendation to project partners (namely Laurel Brake, Jim Mussels and Mark Turner) and faculty that, while the ‘Keyword’ component did not need to be rebuilt, a ‘Facsimile’ component of the website, using a different technical solution, had to be developed. Only with a new facsimile component would KDL have been able to issue a Service Level Agreement for further hosting and maintenance of ncse.
Thanks to support from Birkbeck College at the University of London and the Faculty of Arts and Humanities at King’s College London, in spring-summer 2018 KDL dedicated over 30 days of teamwork to configure a new server for the facsimile component, implement a viewer with browsing and searching functionalities, and associated design interfaces. In addition, using some of the staff 10% exploratory time, some visualisations of the statistics of the periodicals were tested with project partners and added to the site. The KDL development team involved in the project consisted of Paul Caton, Arianna Ciula, Brian Maher, Tiffany Ong and Miguel Vieira. In addition other development team members, including Ginestra Ferraro and Elliott Hall, contributed to the framework ncse 2018 builds on and at different stages of review.
In line with KDL’s practices in Software Development Life Cycle (SDLC), the development approach for the ncse 2018 facsimile edition followed Agile methodology whereby work proceeds in increments and the product is iteratively developed. Unit tests were created to guarantee the quality and sustainability of the code. All the source code is hosted on Github. Work increments addressed priorities requirements as defined with the project partners. Each increment of work was followed by a review to inform the focus of the next work increment and to re-prioritise the requirements. The project employed existing KDL project management tools for issue tracking and documentation.
As explained below the solution architecture developed for the 2018 ncse edition of the facsimile component lavarages KDL efforts to rebuild the site of another legacy project which suffered from obsolescence and security issues, the Masonic Periodicals Online, a digital resource that provides access to the periodicals held by the The Library and Museum of Freemasonry. Note however that the searchable text is still based on the OCRed text created for the 2008 edition.
Technologies and processes
As previously discussed, KDL was unable to reach Olive Software to discuss a replacement solution for the original Olive viewer. Despite best efforts, KDL was unable to find a direct replacement for the legacy Olive Software application.
Research suggests that Olive Software have moved away from their traditional XML workflow running on self-hosted applications, and are utilising cloud technologies to provide an online, more visual, workflow. Olive Software have developed a new core technology, OLIVConnect, which appears to be (KDL can not access the new software) fully online and incompatible with the XML-based workflow from their legacy products.
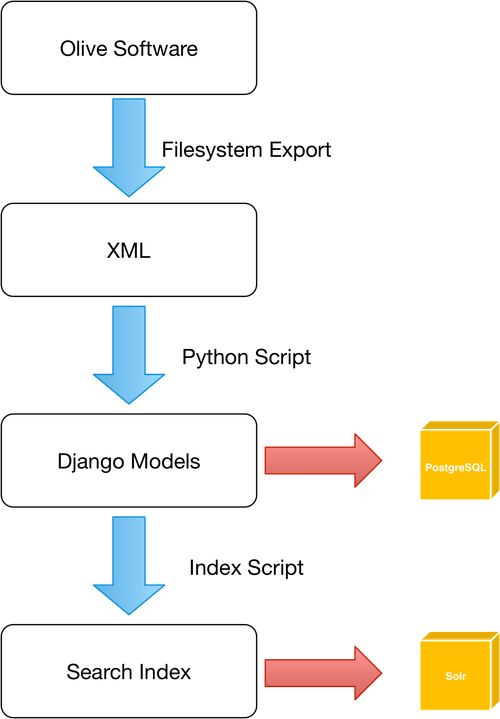
As a consequence KDL designed the replacement application to host the same material as the ncse 2008 edition, using the XML source files recovered from the Olive Software.
All data was stored within Olive Software, and was not available in other repositories. Since the Olive Software had no reasonable export functionality, the only method available to extract the data was to export the raw XML files and repository structure from the Olive Software’s filesystem.
The filesystem directory structure was in the following format:
- High level directory [X]YYY[Z], where [X] is an optional modifier (e.g. F: front matter), YYYY is the publication acronym (e.g. NS: Northern Star) and [Z] is an optional issue label (e.g. 2: second edition).
- Second, third and fourth level subdirectories representing the publication year, month and day.
Contained within this folder were 3 files: a full-text PDF scan of the issue, a Table of Contents (TOC.xml) and an archive, Document.zip. The archive contained:
- Top level directory for each page within the issue.
- Definitions (XML) for each Article (Ar), Advert (Ad) or Picture (Pc) within a page.
- Page contents (XML) - essentially a subtree of TOC.xml
- An Img directory containing multiple thumbnails and images of each article.
Filenames were in the format [Ar|Ad|Pc][Page number][Article number].xml and [Ar|Ad|Pc][Page number][Article number][Image number].png, with [Image number] replaced with S for header images. For example, the third image of the second article on the first page would be Ar0010203.png.
KDL developed a Python script which recursively scanned all XML files for Articles, reconstructing issue metadata from the TOC.xml file. Additional data was taken from the filesystem to aid metadata collection (such as issue numbers), and categories (e.g. Pc for Picture).
Firstly, Publications were created manually, along with their acronyms.
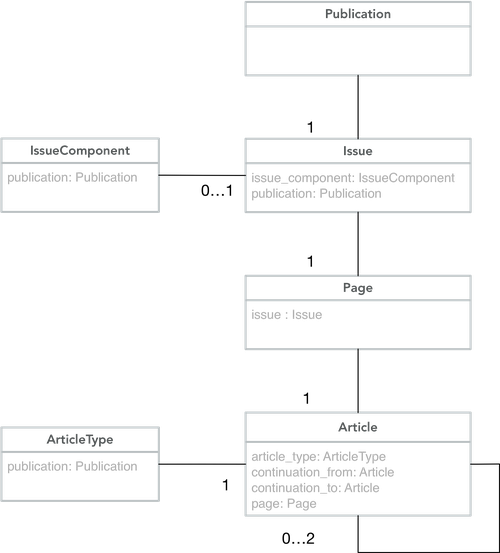
Then, for each issue directory encountered, an Issue was created in the database, assigned to its respective Publication. If the directory structure indicated that this was a component of an issue (e.g. front matter), an Issue component was assigned with the respective component type. As the directory structure was traversed, any page folders found triggered the creation of a new Page object, assigned to the correct Issue.

Articles were imported with their continuations (explained below) and an ArticleType - an authority list of categories including Article, Picture and Ad.
The XML output from the Olive Software split single articles into multiple segments, each having their own bounding box and associated metadata. To replicate this, and in order to display a full article, articles within an issue are stored as a doubly linked list of instances of the Article model, each having a continuation to and continuation from to another instance. For example:
Search Functionality
The application created a search index of all articles, including the OCR generated text forming the article along with relevant metadata including the article title, category, page, issue, date and publication. The article category, date and publication are stored as facet fields, which allows the user interface to filter search results based on these fields. This data is stored in a Solr index for each individual article.
When a search is performed, the application returns a list of matching articles. To obtain the correct match, search results are limited to articles which have no “continuation from” - indicating they form the first part of any given article. The bounding box for the returned article is overlaid onto the image displayed in the user interface, in order to highlight the relevant section of the page.
To highlight search results on an image, the bounding box coordinates for every word on a page are stored in a PostgreSQL JSON field, in the format:
{
‘Word’: [
{
‘x0’ : a, ‘x1’ : b, ‘y0’ : c, ‘y1’ : d
}...
]
}
Where (a, b, c, d) forms the bounding box of an occurance of “Word” on the page. When a free text search is performed, the exact bounding boxes of any words forming the search term are retrieved from the JSON representation. These bounding boxes are then overlaid onto the page image as translucent rectangles, highlighting words forming the search query.
Web Framework
The new Facsimile viewer for ncse has been built using entirely open source components. The underlying operating system, Windows Server 2003, has been replaced with Ubuntu 16.04LTS, which receives regular security and software updates, and is easily upgradable once its guaranteed support period of 5 years expires. The web server layer, formerly Microsoft IIS, has been replaced with 2 open source components - Apache Traffic Server (a reverse proxy which performs advanced caching, proxying, SSL and authentication), and Nginx (web server). Additionally, uwsgi provides an interface between the web server and the Django framework. An overview of the application architecture for ncse is shown below.
All Facsimile data (with the exception of image files and PDFs) is stored in a relational PostgreSQL database - this includes all metadata relating to Publications, Issues, Pages and individual Articles. Facsimile data is highly suited for a relational database, due to there being clear one-to-many relationships between models - for example, a Publication has many Issues, but an Issue has one Publication. This structure allows us to efficiently store and retrieve information with simple database queries.

Functionality for ncse which was provided by Olive Software has been re-written using the Django Web Framework, a highly complex framework for web development, written in the Python programming language. Django is fully open source, and receives regular feature and security updates. Django can be run under many different application and web servers, reducing the dependence on a single application or configuration, as was the demise of the original ncse website 2008 edition. Our current technology stack utilises Nginx and Uwsgi to serve the Django application; however, should the need arise, we can easily run the application under Apache with mod_wsgi with, at worst, minimal changes.
Django provides many features used in ncse, including an object-relational mapping (ORM). The ORM allows us to define platform agnostic models of the data, such as the above Publication-Issue-Page-Article relationship, in a way which is entirely abstracted from the underlying data storage platform. This means that even though we have selected PostgreSQL as the database engine for ncse, if, for any reason, this becomes unsustainable, we can replace this with an alternative relational database engine with no code modifications. As with the Django framework described above, this further reduces our reliance on any single application, and allows for greater flexibility if any future issues arise with our technology stack.
In addition to Django itself, in order to provide an advanced and faceted search interface, we use the Django-haystack framework. Django-haystack provides complex indexing functionality for data which has been modelled using Django, in addition to advanced APIs for searching and filtering results. Django-haystack supports multiple search engines, of which we have selected Solr for ncse, since it has shown to provide increased performance and reliability when searching large data sets (ncse has 477,000 items in its search index). We utilise the faceted search functionality of Solr to provide the ability to filter search results by Publication, Date, and Category, in addition to allowing free text searching of the entire database of OCR-generated text.
Design Process
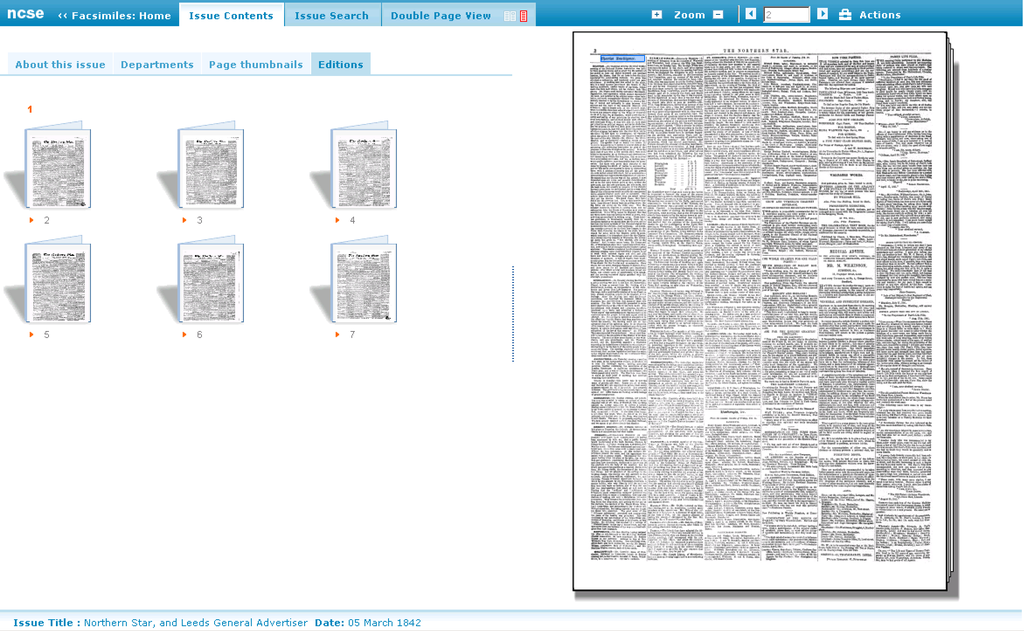
Since the backend was been restructured, KDL took the opportunity to redesign the frontend, taking to account the partners’ feedback of what features users found useful in the 2008 facsimiles edition. Below is a screenshot of the 2008 ncse facsimiles interface.
The amount of resources available to design the 2018 edition was limited so only selected improvements could be made. Our focus was to make the user journey and navigation smoother through the two main facsimile pathways, “explore” and “search”. We drew out a site map to outline the possible routes.
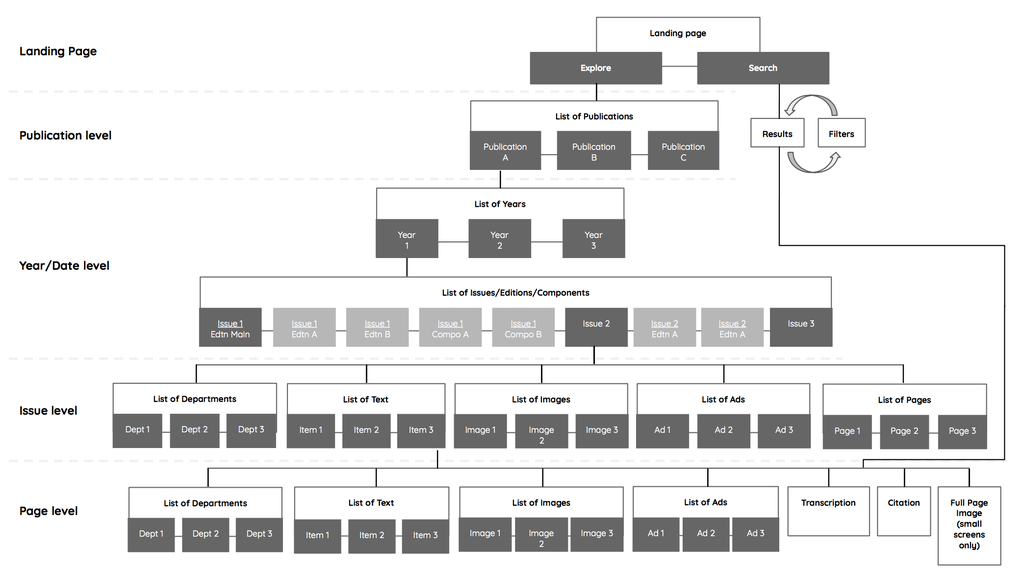
Basic site map
With the “explore” pathway, we wanted to enhance the methods of navigation by having an accordion left sidebar listing showing the breakdown of various categories like dates, editions, components, or items, and listing the data counts. On the right of the “explore” pages, the visual counterpart features an image thumbnail of either the publication pages or items, along with more metadata.
With respect to the “search” pathway, we kept the search form fairly simple but added filter categories to assist users in refining their search and also added data counts to provide more information.
In the page view, we wanted to repeat what we did in the explore pages, of having the visual and verbal data side by side. So on the left of the screen, the user accesses the page image, and on the right, the breakdown of items on the page, and the transcription so it could be read side by side with the original image.
Since the data counts were a large part of the interface, we thought it would be useful to aggregate some of that data to reveal some of the statistical aspects of ncse that cannot be deduced from the textual descriptions. On the facsimile page, the compiled data visualisation graphs feature a timeline of all the publications, while the individual publication graphs present the amount of items: text, pictures, ads.
The interface was adapted to be usable on small screens such as mobile devices where some of the features described above will function in a slightly differently.
1. For further information on KDL archiving and sustainability process see: Smithies, J., Sichani, A.M., & Westling, C. (2017). Preserving 30 years of Digital Humanities Work: The Experience of King’s College London Digital Lab. Presented at the DPASSH: Digital Preservation for Social Sciences and Humanities, University of Sussex; Smithies, J., P. Caton, G. Ferraro, L. Figueira, E. Hall, N. Jakeman, P. Mellen, A.M. Sicani, M. Vieira, T. Watts, Carina Westling. (2017). Mechanizing the Humanities? King’s Digital Lab as Critical Experiment. Presented at the DH2017, McGill University, Montreal. ↩